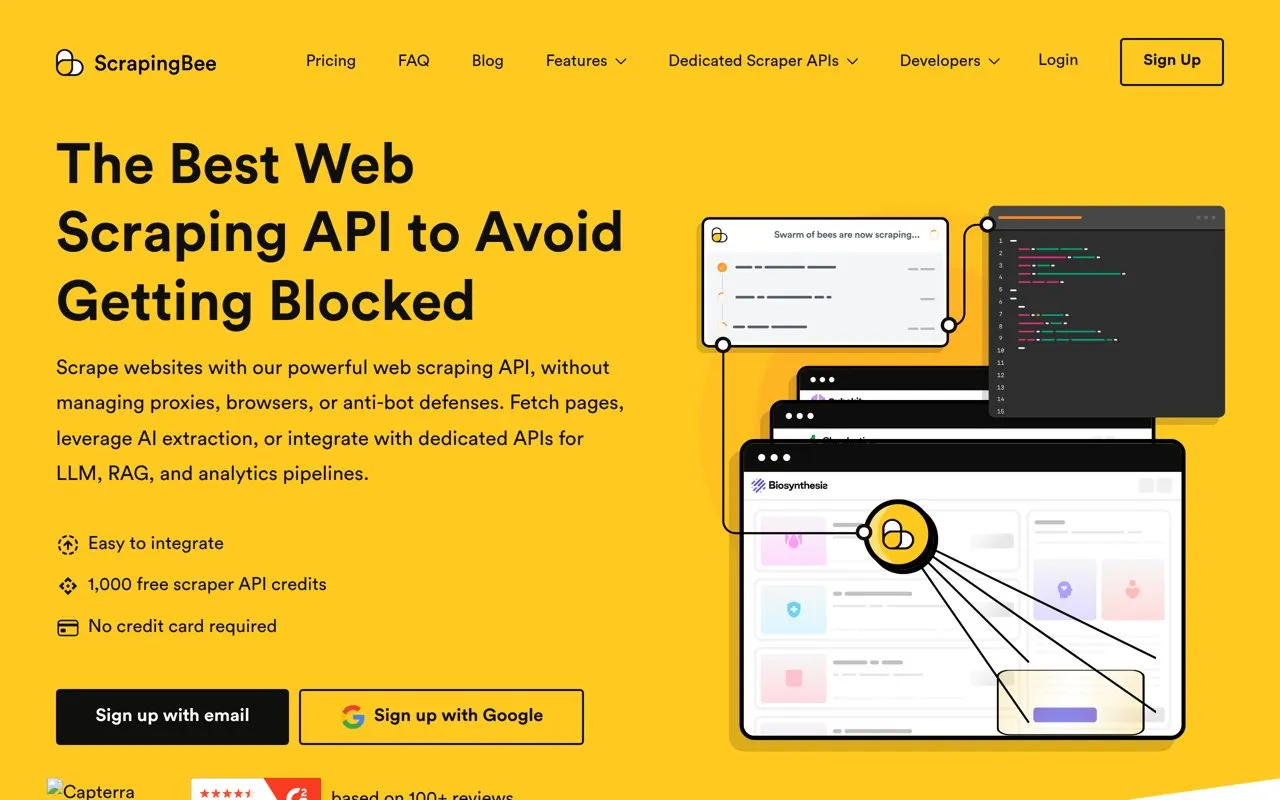
ScrapingBee API
Une API de scraping simple qui gère navigateurs headless et proxies pour vous.
ScrapingBee est une API de web scraping qui se charge de la rotation de proxies, du rendu JavaScript via navigateur headless et du contournement des protections anti-bot. On envoie une URL et l'API renvoie le HTML rendu, une capture d'écran ou des données déjà extraites. Pensée pour une intégration rapide, elle s'adresse aux développeurs et équipes data qui veulent scraper sans gérer leur propre parc de proxies ni de navigateurs.
Que propose l'API ScrapingBee ?
Tarifs de l'API ScrapingBee
Abonnement mensuel par paliers de crédits API. Chaque requête consomme un nombre de crédits variable selon les options : rendu JavaScript, proxies premium ou stealth augmentent le coût par appel.
Offre gratuite — 1 000 crédits API offerts à l'inscription, sans carte bancaire, pour tester l'API avant de souscrire un abonnement.
Authentification & intégration
Authentification par clé API privée : la clé du compte est transmise à chaque requête (paramètre api_key dans l'URL de l'API).
API REST synchrone : on appelle l'endpoint avec l'URL cible et les options voulues, la réponse est renvoyée immédiatement. Options activables par requête : render_js pour le rendu JavaScript (5 crédits), premium_proxy ou stealth_proxy pour les sites difficiles (jusqu'à 75 crédits), geotargeting par pays, extract_rules ou ai_query pour l'extraction. Un mode proxy classique est aussi disponible.
Cas d'usage de l'API ScrapingBee
- Scraper des pages dynamiques en JavaScript sans gérer soi-même un navigateur headless.
- Extraire des résultats de recherche Google structurés via la Google Search API.
- Récupérer des fiches produits et prix e-commerce (Amazon, Walmart) via les scrapers dédiés.
- Obtenir directement du JSON structuré grâce à l'extraction par règles CSS ou par IA.
- Générer des captures d'écran automatisées de pages web pour la veille ou le monitoring.
- Contourner les protections anti-bot des sites difficiles avec les proxies premium ou stealth.
✓ Points forts
- Intégration simple et rapide via une API REST claire et bien documentée.
- Gère automatiquement rendu JavaScript, rotation de proxies et anti-bot.
- Extraction de données intégrée par règles CSS ou par IA, sans parser le HTML soi-même.
- Endpoints dédiés (Google, Amazon, etc.) et capture d'écran en plus du scraping HTML.
- 1 000 crédits gratuits pour tester sans carte bancaire.
⚠ Limites
- Le rendu JavaScript et les proxies premium/stealth consomment beaucoup plus de crédits par requête.
- Pas de palier gratuit permanent : un abonnement mensuel est requis après l'essai.
- Les fonctionnalités avancées (JS, proxies premium, geotargeting) ne sont disponibles qu'à partir des plans plus chers.
- Service orienté développeurs : l'intégration et le traitement des résultats restent à votre charge.
Questions fréquentes sur l'API ScrapingBee
ScrapingBee est-il gratuit ?
Non, c'est un service payant par abonnement, mais l'inscription offre 1 000 crédits API gratuits, sans carte bancaire, pour tester l'API avant de choisir un plan.
Comment fonctionne le coût en crédits ?
Chaque requête consomme des crédits selon les options : une requête avec rendu JavaScript coûte 5 crédits, avec proxy premium jusqu'à 10 ou 25 crédits, et avec proxy stealth jusqu'à 75 crédits. Le nombre de crédits inclus dépend du plan.
ScrapingBee gère-t-il le JavaScript ?
Oui, l'API rend le JavaScript via un navigateur headless lorsque l'option render_js est activée, ce qui permet de scraper des pages dynamiques sans gérer soi-même un navigateur.
Peut-on extraire des données structurées ?
Oui, ScrapingBee propose l'extraction par règles CSS (extract_rules) et l'extraction assistée par IA (ai_query) pour récupérer directement du JSON structuré au lieu du HTML brut.
Quelle authentification utilise l'API ?
Une clé API privée liée au compte, transmise à chaque requête via le paramètre api_key dans l'URL de l'appel.
ScrapingBee vs ScraperAPI : lequel choisir ?
ScrapingBee mise sur la simplicité d'intégration et l'extraction de données intégrée (CSS et IA), tandis que ScraperAPI met l'accent sur le volume, la forte concurrence et un outil no-code. Le choix dépend du besoin d'extraction intégrée face au volume brut.